
Blue Iris and CodeProject.AI ALPR
- Thread starter MikeLud1
- Start date
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
I am running yolo 5 on my boxes, do we think there will be a patch or something to this? Or we will have to do this manuallyIt did help me with a similar error for YOLOv8 after update to 2.6.5 - that's actually my post in there")
No clue. I think NumPy was upgraded to 2.0 while the modules themselves were compiled under NumPy 1.x - hence the error.
I have downgraded NumPy manually to 1.23.0 and managed to revive YOLOv8.
It's actually something that I asked ChatGPT how to fix - and its response helped a lot
I have downgraded NumPy manually to 1.23.0 and managed to revive YOLOv8.
It's actually something that I asked ChatGPT how to fix - and its response helped a lot

Ya going to have to tapout on this, beyond my skillset and time, tried a few different things that you and chatgpt suggested, no joy. Anyways thx for the repliesNo clue. I think NumPy was upgraded to 2.0 while the modules themselves were compiled under NumPy 1.x - hence the error.
I have downgraded NumPy manually to 1.23.0 and managed to revive YOLOv8.
It's actually something that I asked ChatGPT how to fix - and its response helped a lot
@MikeLud1 - I just updated to the newest CPAI and the ANPR is not working. Gives this error:
18:20:02:ALPR_adapter.py: RuntimeError: module compiled against ABI version 0x1000009 but this version of numpy is 0x2000000
18:20:02:ALPR_adapter.py: Traceback (most recent call last):
18:20:02:ALPR_adapter.py: File "C:\Program Files\CodeProject\AI\modules\ALPR\ALPR_adapter.py", line 16, in
18:20:02:ALPR_adapter.py: from ALPR import init_detect_platenumber, detect_platenumber
18:20:02:ALPR_adapter.py: File "C:\Program Files\CodeProject\AI\modules\ALPR\ALPR.py", line 7, in
18:20:02:ALPR_adapter.py: import utils.tools as tool
18:20:02:ALPR_adapter.py: File "C:\Program Files\CodeProject\AI\modules\ALPR\utils\tools.py", line 2, in
18:20:02:ALPR_adapter.py: import cv2
18:20:02:ALPR_adapter.py: File "C:\Program Files\CodeProject\AI\modules\ALPR\bin\windows\python39\venv\lib\site-packages\cv2\init.py", line 181, in
18:20:02:ALPR_adapter.py: bootstrap()
18:20:02:ALPR_adapter.py: File "C:\Program Files\CodeProject\AI\modules\ALPR\bin\windows\python39\venv\lib\site-packages\cv2\init.py", line 153, in bootstrap
18:20:02:ALPR_adapter.py: native_module = importlib.import_module("cv2")
18:20:02:ALPR_adapter.py: File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python39\lib\importlib\init.py", line 127, in import_module
18:20:02:ALPR_adapter.py: return _bootstrap._gcd_import(name[level:], package, level)
18:20:02:ALPR_adapter.py: ImportError: numpy.core.multiarray failed to import
18:20:02:ALPR_adapter.py: RuntimeError: module compiled against ABI version 0x1000009 but this version of numpy is 0x2000000
18:20:02:ALPR_adapter.py: Traceback (most recent call last):
18:20:02:ALPR_adapter.py: File "C:\Program Files\CodeProject\AI\modules\ALPR\ALPR_adapter.py", line 16, in
18:20:02:ALPR_adapter.py: from ALPR import init_detect_platenumber, detect_platenumber
18:20:02:ALPR_adapter.py: File "C:\Program Files\CodeProject\AI\modules\ALPR\ALPR.py", line 7, in
18:20:02:ALPR_adapter.py: import utils.tools as tool
18:20:02:ALPR_adapter.py: File "C:\Program Files\CodeProject\AI\modules\ALPR\utils\tools.py", line 2, in
18:20:02:ALPR_adapter.py: import cv2
18:20:02:ALPR_adapter.py: File "C:\Program Files\CodeProject\AI\modules\ALPR\bin\windows\python39\venv\lib\site-packages\cv2\init.py", line 181, in
18:20:02:ALPR_adapter.py: bootstrap()
18:20:02:ALPR_adapter.py: File "C:\Program Files\CodeProject\AI\modules\ALPR\bin\windows\python39\venv\lib\site-packages\cv2\init.py", line 153, in bootstrap
18:20:02:ALPR_adapter.py: native_module = importlib.import_module("cv2")
18:20:02:ALPR_adapter.py: File "C:\Program Files\CodeProject\AI\runtimes\bin\windows\python39\lib\importlib\init.py", line 127, in import_module
18:20:02:ALPR_adapter.py: return _bootstrap._gcd_import(name[level:], package, level)
18:20:02:ALPR_adapter.py: ImportError: numpy.core.multiarray failed to import
@wittaj see my replies above, I managed to downgrade NumPy to below 2.0 and at least YOLOv8 (which I am using) works.
I expect the same thing to be valid for ALPR, which I admit I gave up on, since I spent an enormous amount of time trying to get working, without success.
What I mean is, it loads, it attempts to detect license plates, and detects nothing, while other (paid) solutions detect license plates from the very same images without issues.
But I digress.
At any rate, what you experience is caused by NumPy being upgraded to 2.0, while the ALPR module itself is compiled with NumPy version smaller than 2.0.
Rather than attempting top recompile the module, I downgraded NumPy, which was easier.
ChatGPT to the rescue
I expect the same thing to be valid for ALPR, which I admit I gave up on, since I spent an enormous amount of time trying to get working, without success.
What I mean is, it loads, it attempts to detect license plates, and detects nothing, while other (paid) solutions detect license plates from the very same images without issues.
But I digress.
At any rate, what you experience is caused by NumPy being upgraded to 2.0, while the ALPR module itself is compiled with NumPy version smaller than 2.0.
Rather than attempting top recompile the module, I downgraded NumPy, which was easier.
ChatGPT to the rescue
tinker3433
BIT Beta Team
- May 3, 2014
- 31
- 11
This fixed my ALPR issue that had the same symptoms. I just changed to the identical path, but with /ALPR/place of /ObjectDetectionYOLOv8/Maybe this helps.
hubbend
n3wb
Installing the new version, 3.2.2, but it fails to install paddlepaddle
2024-06-29 08:32:39: - Installing PaddlePaddle, Parallel Distributed Deep Learning...(⌠failed check) done
which leads to problems when it tries to apply the paddleOCR patch.
I re-ran setup with verbosity set to loud and this is the paddlepaddle info:
If I (on my mac)
wget
I can get the index.html which has the links to all the various protobuf versions. Is this an issue on Baidu's part or ???
Someone found that linstalling PaddlePaddle from the venv fixed the issue. It uninstalled protobuf 5.27.2 which got installed with ALPR 3.2.2 and installed protobuf 3.20.2 which is what is needed.
2024-06-29 08:32:39: - Installing PaddlePaddle, Parallel Distributed Deep Learning...(⌠failed check) done
which leads to problems when it tries to apply the paddleOCR patch.
2024-06-29 08:31:44: Installing CodeProject.AI Analysis Module
2024-06-29 08:31:44: ======================================================================
2024-06-29 08:31:44: CodeProject.AI Installer
2024-06-29 08:31:44: ======================================================================
2024-06-29 08:31:44: 28.8Gb of 235Gb available on Windows
2024-06-29 08:31:44: General CodeProject.AI setup
2024-06-29 08:31:44: Creating Directories...done
2024-06-29 08:31:44: GPU support
2024-06-29 08:31:45: CUDA Present...Yes (CUDA 11.8, cuDNN 9.0)
2024-06-29 08:31:45: ROCm Present...No
2024-06-29 08:31:45: Checking for .NET 7.0...Checking SDKs...All good. .NET is 7.0.410
2024-06-29 08:31:48: Reading ALPR settings.......done
2024-06-29 08:31:48: Installing module License Plate Reader 3.2.2
2024-06-29 08:31:48: Installing Python 3.9
2024-06-29 08:31:48: Python 3.9 is already installed
2024-06-29 08:31:57: Creating Virtual Environment (Local)...done
2024-06-29 08:31:57: Confirming we have Python 3.9 in our virtual environment...present
2024-06-29 08:31:57: Downloading ALPR models...already exists...Expanding...done.
2024-06-29 08:31:58: Copying contents of ocr-en-pp_ocrv4-paddle.zip to paddleocr...done
2024-06-29 08:31:58: Installing Python packages for License Plate Reader
2024-06-29 08:31:58: [0;Installing GPU-enabled libraries: If available
2024-06-29 08:32:00: Ensuring Python package manager (pip) is installed...done
2024-06-29 08:32:12: Ensuring Python package manager (pip) is up to date...done
2024-06-29 08:32:12: Python packages specified by requirements.windows.cuda11_8.txt
2024-06-29 08:32:26: - Installing NumPy, a package for scientific computing...(✅ checked) done
2024-06-29 08:32:39: - Installing PaddlePaddle, Parallel Distributed Deep Learning...(⌠failed check) done
2024-06-29 08:34:46: - Installing PaddleOCR, the OCR toolkit based on PaddlePaddle...(✅ checked) done
2024-06-29 08:34:50: - Installing imutils, the image utilities library...(✅ checked) done
2024-06-29 08:34:51: - Installing Pillow, a Python Image Library...Already installed
2024-06-29 08:34:51: - Installing OpenCV, the Computer Vision library for Python...Already installed
2024-06-29 08:35:02: - Installing the CodeProject.AI SDK...(✅ checked) done
2024-06-29 08:35:02: Installing Python packages for the CodeProject.AI Server SDK
2024-06-29 08:35:05: Ensuring Python package manager (pip) is installed...done
2024-06-29 08:35:07: Ensuring Python package manager (pip) is up to date...done
2024-06-29 08:35:07: Python packages specified by requirements.txt
2024-06-29 08:35:08: - Installing Pillow, a Python Image Library...Already installed
2024-06-29 08:35:09: - Installing Charset normalizer...Already installed
2024-06-29 08:35:10: - Installing aiohttp, the Async IO HTTP library...Already installed
2024-06-29 08:35:11: - Installing aiofiles, the Async IO Files library...Already installed
2024-06-29 08:35:12: - Installing py-cpuinfo to allow us to query CPU info...Already installed
2024-06-29 08:35:13: - Installing Requests, the HTTP library...Already installed
2024-06-29 08:35:13: Scanning modulesettings for downloadable models...No models specified
2024-06-29 08:35:13: Executing post-install script for License Plate Reader
2024-06-29 08:35:13: Applying PaddleOCR patch
2024-06-29 08:35:13: 1 file(s) copied.
2024-06-29 08:35:15: Traceback (most recent call last):
2024-06-29 08:35:15: File "C:\Program Files\CodeProject\AI\modules\ALPR\ALPR_adapter.py", line 11, in <module>
2024-06-29 08:35:15: from ALPR import init_detect_platenumber, detect_platenumber
2024-06-29 08:35:15: File "C:\Program Files\CodeProject\AI\modules\ALPR\ALPR.py", line 17, in <module>
2024-06-29 08:35:15: from paddleocr import PaddleOCR
2024-06-29 08:35:15: File "C:\Program Files\CodeProject\AI\modules\ALPR\bin\windows\python39\venv\lib\site-packages\paddleocr\init.py", line 14, in <module>
2024-06-29 08:35:15: from .paddleocr import *
2024-06-29 08:35:15: File "C:\Program Files\CodeProject\AI\modules\ALPR\bin\windows\python39\venv\lib\site-packages\paddleocr\paddleocr.py", line 21, in <module>
2024-06-29 08:35:15: import paddle
2024-06-29 08:35:15: ModuleNotFoundError: No module named 'paddle'
2024-06-29 08:35:15: Self test: Self-test passed
2024-06-29 08:35:15: Module setup time 00:03:29.20
2024-06-29 08:35:15: Setup complete
2024-06-29 08:35:15: Total setup time 00:03:31.29
Installer exited with code 0
2024-06-29 08:31:44: ======================================================================
2024-06-29 08:31:44: CodeProject.AI Installer
2024-06-29 08:31:44: ======================================================================
2024-06-29 08:31:44: 28.8Gb of 235Gb available on Windows
2024-06-29 08:31:44: General CodeProject.AI setup
2024-06-29 08:31:44: Creating Directories...done
2024-06-29 08:31:44: GPU support
2024-06-29 08:31:45: CUDA Present...Yes (CUDA 11.8, cuDNN 9.0)
2024-06-29 08:31:45: ROCm Present...No
2024-06-29 08:31:45: Checking for .NET 7.0...Checking SDKs...All good. .NET is 7.0.410
2024-06-29 08:31:48: Reading ALPR settings.......done
2024-06-29 08:31:48: Installing module License Plate Reader 3.2.2
2024-06-29 08:31:48: Installing Python 3.9
2024-06-29 08:31:48: Python 3.9 is already installed
2024-06-29 08:31:57: Creating Virtual Environment (Local)...done
2024-06-29 08:31:57: Confirming we have Python 3.9 in our virtual environment...present
2024-06-29 08:31:57: Downloading ALPR models...already exists...Expanding...done.
2024-06-29 08:31:58: Copying contents of ocr-en-pp_ocrv4-paddle.zip to paddleocr...done
2024-06-29 08:31:58: Installing Python packages for License Plate Reader
2024-06-29 08:31:58: [0;Installing GPU-enabled libraries: If available
2024-06-29 08:32:00: Ensuring Python package manager (pip) is installed...done
2024-06-29 08:32:12: Ensuring Python package manager (pip) is up to date...done
2024-06-29 08:32:12: Python packages specified by requirements.windows.cuda11_8.txt
2024-06-29 08:32:26: - Installing NumPy, a package for scientific computing...(✅ checked) done
2024-06-29 08:32:39: - Installing PaddlePaddle, Parallel Distributed Deep Learning...(⌠failed check) done
2024-06-29 08:34:46: - Installing PaddleOCR, the OCR toolkit based on PaddlePaddle...(✅ checked) done
2024-06-29 08:34:50: - Installing imutils, the image utilities library...(✅ checked) done
2024-06-29 08:34:51: - Installing Pillow, a Python Image Library...Already installed
2024-06-29 08:34:51: - Installing OpenCV, the Computer Vision library for Python...Already installed
2024-06-29 08:35:02: - Installing the CodeProject.AI SDK...(✅ checked) done
2024-06-29 08:35:02: Installing Python packages for the CodeProject.AI Server SDK
2024-06-29 08:35:05: Ensuring Python package manager (pip) is installed...done
2024-06-29 08:35:07: Ensuring Python package manager (pip) is up to date...done
2024-06-29 08:35:07: Python packages specified by requirements.txt
2024-06-29 08:35:08: - Installing Pillow, a Python Image Library...Already installed
2024-06-29 08:35:09: - Installing Charset normalizer...Already installed
2024-06-29 08:35:10: - Installing aiohttp, the Async IO HTTP library...Already installed
2024-06-29 08:35:11: - Installing aiofiles, the Async IO Files library...Already installed
2024-06-29 08:35:12: - Installing py-cpuinfo to allow us to query CPU info...Already installed
2024-06-29 08:35:13: - Installing Requests, the HTTP library...Already installed
2024-06-29 08:35:13: Scanning modulesettings for downloadable models...No models specified
2024-06-29 08:35:13: Executing post-install script for License Plate Reader
2024-06-29 08:35:13: Applying PaddleOCR patch
2024-06-29 08:35:13: 1 file(s) copied.
2024-06-29 08:35:15: Traceback (most recent call last):
2024-06-29 08:35:15: File "C:\Program Files\CodeProject\AI\modules\ALPR\ALPR_adapter.py", line 11, in <module>
2024-06-29 08:35:15: from ALPR import init_detect_platenumber, detect_platenumber
2024-06-29 08:35:15: File "C:\Program Files\CodeProject\AI\modules\ALPR\ALPR.py", line 17, in <module>
2024-06-29 08:35:15: from paddleocr import PaddleOCR
2024-06-29 08:35:15: File "C:\Program Files\CodeProject\AI\modules\ALPR\bin\windows\python39\venv\lib\site-packages\paddleocr\init.py", line 14, in <module>
2024-06-29 08:35:15: from .paddleocr import *
2024-06-29 08:35:15: File "C:\Program Files\CodeProject\AI\modules\ALPR\bin\windows\python39\venv\lib\site-packages\paddleocr\paddleocr.py", line 21, in <module>
2024-06-29 08:35:15: import paddle
2024-06-29 08:35:15: ModuleNotFoundError: No module named 'paddle'
2024-06-29 08:35:15: Self test: Self-test passed
2024-06-29 08:35:15: Module setup time 00:03:29.20
2024-06-29 08:35:15: Setup complete
2024-06-29 08:35:15: Total setup time 00:03:31.29
Installer exited with code 0
I re-ran setup with verbosity set to loud and this is the paddlepaddle info:
Code:
- Installing PaddlePaddle, Parallel Distributed Deep Learning...Looking in indexes: https://mirror.baidu.com/pypi/simple
Collecting paddlepaddle-gpu==2.6.0
Downloading https://mirror.baidu.com/pypi/packages/37/9f/69921f0e4a5ef25291c77c16775457075559b0f01f7ebcdc1ea66abf2451/paddlepaddle_gpu-2.6.0-cp39-cp39-win_amd64.whl (476.3 MB)
---------------------------------------- 476.3/476.3 MB 1.1 MB/s eta 0:00:00
Collecting httpx (from paddlepaddle-gpu==2.6.0)
Downloading https://mirror.baidu.com/pypi/packages/41/7b/ddacf6dcebb42466abd03f368782142baa82e08fc0c1f8eaa05b4bae87d5/httpx-0.27.0-py3-none-any.whl (75 kB)
---------------------------------------- 75.6/75.6 kB 2.1 MB/s eta 0:00:00
Collecting numpy>=1.13 (from paddlepaddle-gpu==2.6.0)
Downloading https://mirror.baidu.com/pypi/packages/6a/1e/1d76829f03b7ac9c90e2b158f06b69cddf9a06b96667dd7e2d96acdc0593/numpy-2.0.0-cp39-cp39-win_amd64.whl (16.5 MB)
---------------------------------------- 16.5/16.5 MB 8.2 MB/s eta 0:00:00
Collecting Pillow (from paddlepaddle-gpu==2.6.0)
Downloading https://mirror.baidu.com/pypi/packages/0b/d7/3a9cfa80a3ff59fddfe3b5bd1cf5728e7ed6608678ce9f23e79f35e87805/pillow-10.3.0-cp39-cp39-win_amd64.whl (2.5 MB)
---------------------------------------- 2.5/2.5 MB 8.1 MB/s eta 0:00:00
Collecting decorator (from paddlepaddle-gpu==2.6.0)
Downloading https://mirror.baidu.com/pypi/packages/d5/50/83c593b07763e1161326b3b8c6686f0f4b0f24d5526546bee538c89837d6/decorator-5.1.1-py3-none-any.whl (9.1 kB)
Collecting astor (from paddlepaddle-gpu==2.6.0)
Downloading https://mirror.baidu.com/pypi/packages/c3/88/97eef84f48fa04fbd6750e62dcceafba6c63c81b7ac1420856c8dcc0a3f9/astor-0.8.1-py2.py3-none-any.whl (27 kB)
Collecting opt-einsum==3.3.0 (from paddlepaddle-gpu==2.6.0)
Downloading https://mirror.baidu.com/pypi/packages/bc/19/404708a7e54ad2798907210462fd950c3442ea51acc8790f3da48d2bee8b/opt_einsum-3.3.0-py3-none-any.whl (65 kB)
---------------------------------------- 65.5/65.5 kB 506.8 kB/s eta 0:00:00
WARNING: Skipping page https://mirror.baidu.com/pypi/simple/protobuf/ because the GET request got Content-Type: application/octet-stream. The only supported Content-Types are application/vnd.pypi.simple.v1+json, application/vnd.pypi.simple.v1+html, and text/html
INFO: pip is looking at multiple versions of paddlepaddle-gpu to determine which version is compatible with other requirements. This could take a while.
ERROR: Could not find a version that satisfies the requirement protobuf<=3.20.2,>=3.1.0; platform_system == "Windows" (from paddlepaddle-gpu) (from versions: none)
ERROR: No matching distribution found for protobuf<=3.20.2,>=3.1.0; platform_system == "Windows"
(❌ failed check) doneIf I (on my mac)
wget
I can get the index.html which has the links to all the various protobuf versions. Is this an issue on Baidu's part or ???
Someone found that linstalling PaddlePaddle from the venv fixed the issue. It uninstalled protobuf 5.27.2 which got installed with ALPR 3.2.2 and installed protobuf 3.20.2 which is what is needed.
Last edited:
I believe specifically installing CUDA 11.8 does not work, I will try later with CUDA 11.7.
Hi hubbend the link there doesn't work, can you try to find the correct link for me please? Thank you
Someone found that installing PaddlePaddle from the venv fixed the issue. It uninstalled protobuf 5.27.2 which got installed with ALPR 3.2.2 and installed protobuf 3.20.2 which is what is needed.
Hi hubbend the link there doesn't work, can you try to find the correct link for me please?
Thank youhubbend
n3wb
I believe specifically installing CUDA 11.8 does not work, I will try later with CUDA 11.7.
Hi hubbend the link there doesn't work, can you try to find the correct link for me please?
I updated the link but here it is Re: ALPR INSTALLATION, NO MODULE NAME "PADDLE"
hxhoang
n3wb
I updated the link but here it is Re: ALPR INSTALLATION, NO MODULE NAME "PADDLE"
Thanks for the link. ALPR with Cuda 11.8 started OK after I installed PaddlePaddle manually per instruction.
However, ALPR stuck at CPU only, and I had to as well install "pip install PaddlePaddle-gpu" to switch to GPU(CUDA).
derekkoopowitz
n3wb
Thanks for the link. ALPR with Cuda 11.8 started OK after I installed PaddlePaddle manually per instruction.
However, ALPR stuck at CPU only, and I had to as well install "pip install PaddlePaddle-gpu" to switch to GPU(CUDA).
I tried the above and got the following error:
ERROR: Could not install packages due to an OSError: [WinError 5] Access is denied: 'c:\\program files\\codeproject\\ai\\modules\\alpr\\bin\\windows\\python39\\venv\\Lib\\site-packages\\paddle\\base\\libpaddle.pyd'
Check the permissions.
My install of the non gpu paddle worked well.
hxhoang
n3wb
Have you tried Command Prompt in Admin mode?I tried the above and got the following error:
ERROR: Could not install packages due to an OSError: [WinError 5] Access is denied: 'c:\\program files\\codeproject\\ai\\modules\\alpr\\bin\\windows\\python39\\venv\\Lib\\site-packages\\paddle\\base\\libpaddle.pyd'
Check the permissions.
My install of the non gpu paddle worked well.
derekkoopowitz
n3wb
hxhoang
n3wb
Steps I used to install PaddlePaddle-gpu on my system (similar to instruction in the link except PaddlePaddle-gpu instead of PaddlePaddle):Definitely.
My CodeProject and BI are on Promox VM Windows 11.
---------------------------------------------
1. Open Command Prompt in Admin mode
2. Run the below commands:
cd \Program Files\CodeProject\AI\modules\ALPR\bin\windows\python39\venv\Scripts
activate
cd C:\Program Files\CodeProject\AI\modules\ALPR
pip install PaddlePaddle-gpu
--------------------------------------
After that I noticed that there were 2 folders: "paddlepaddle_gpu-2.6.1.dist-info" and "paddlepaddle-2.6.1.dist-info" under C:\Program Files\CodeProject\AI\modules\ALPR\bin\windows\python39\venv\Lib\site-packages
derekkoopowitz
n3wb
Steps I used to install PaddlePaddle-gpu on my system (similar to instruction in the link except PaddlePaddle-gpu instead of PaddlePaddle):
My CodeProject and BI are on Promox VM Windows 11.
---------------------------------------------
1. Open Command Prompt in Admin mode
2. Run the below commands:
cd \Program Files\CodeProject\AI\modules\ALPR\bin\windows\python39\venv\Scripts
activate
cd C:\Program Files\CodeProject\AI\modules\ALPR
pip install PaddlePaddle-gpu
--------------------------------------
After that I noticed that there were 2 folders: "paddlepaddle_gpu-2.6.1.dist-info" and "paddlepaddle-2.6.1.dist-info" under C:\Program Files\CodeProject\AI\modules\ALPR\bin\windows\python39\venv\Lib\site-packages
See the attached screenshot... no joy.
EDIT: I uninstalled ALPR - deleted the folder and then reinstalled ALPR. Installed Paddle manually and then did the install for the GPU version and this time it worked.
Attachments
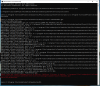
Last edited:
hopalong
Getting the hang of it
I just installed a Tesla P4 8GB in my unraid server for CP.AI. Pulled this tag codeproject/ai-server:cuda12_2-2.6.5 . Which version of Yolo should I be using for that and is ALPR able to use this GPU?
When ever I try to enable GPU for the LPR it keeps going back to CPU.

Here is the LPR Info where it shows GPU libraries are not installed:
Here is the system info:
When ever I try to enable GPU for the LPR it keeps going back to CPU.
Here is the LPR Info where it shows GPU libraries are not installed:
Code:
Module 'License Plate Reader' 3.2.2 (ID: ALPR)
Valid: True
Module Path: <root>/modules/ALPR
Module Location: Internal
AutoStart: True
Queue: alpr_queue
Runtime: python3.8
Runtime Location: Local
FilePath: ALPR_adapter.py
Start pause: 3 sec
Parallelism: 0
LogVerbosity:
Platforms: all,!windows-arm64
GPU Libraries: not installed
GPU: use if supported
Accelerator:
Half Precision: enable
Environment Variables
AUTO_PLATE_ROTATE = True
CROPPED_PLATE_DIR = <root>/Server/wwwroot
MIN_COMPUTE_CAPABILITY = 6
MIN_CUDNN_VERSION = 7
OCR_OPTIMAL_CHARACTER_HEIGHT = 60
OCR_OPTIMAL_CHARACTER_WIDTH = 30
OCR_OPTIMIZATION = True
PLATE_CONFIDENCE = 0.7
PLATE_RESCALE_FACTOR = 2
PLATE_ROTATE_DEG = 0
REMOVE_SPACES = False
ROOT_PATH = <root>
SAVE_CROPPED_PLATE = False
Status Data: {
"inferenceDevice": "CPU",
"inferenceLibrary": "",
"canUseGPU": "false",
"successfulInferences": 19,
"failedInferences": 0,
"numInferences": 19,
"averageInferenceMs": 138.0
}
Started: 28 Jul 2024 12:52:06 PM Pacific Standard Time
LastSeen: 28 Jul 2024 12:52:37 PM Pacific Standard Time
Status: Started
Requests: 16112 (includes status calls)Here is the system info:
Code:
Server version: 2.6.5
System: Docker (b942b79acfaf)
Operating System: Linux (Ubuntu 22.04)
CPUs: Intel(R) Xeon(R) CPU E3-1230 V2 @ 3.30GHz (Intel)
1 CPU x 4 cores. 8 logical processors (x64)
GPU (Primary): Tesla P4 (8 GiB) (NVIDIA)
Driver: 550.40.07, CUDA: 11.5.119 (up to: 12.4), Compute: 6.1, cuDNN: 8.9.6
System RAM: 16 GiB
Platform: Linux
BuildConfig: Release
Execution Env: Docker
Runtime Env: Production
Runtimes installed:
.NET runtime: 7.0.19
.NET SDK: Not found
Default Python: 3.10.12
Go: Not found
NodeJS: Not found
Rust: Not found
Video adapter info:
System GPU info:
GPU 3D Usage 13%
GPU RAM Usage 1.3 GiB
Global Environment variables:
CPAI_APPROOTPATH = <root>
CPAI_PORT = 32168
Last edited:
Interloper
n3wb
Apologies in advance if this is common knowledge, but I seem to be having a hard time finding info for this. I just need people, animals, vehicles, and LPR. Is there a succinct answer to this?
Can you explain what the * symbol represents? If I just wanted animals, people, and/or LPR how can I filter out the rest? I get bombarded with flying insect frisbee alerts
View attachment 194661
hxhoang
n3wb
I just installed a Tesla P4 8GB in my unraid server for CP.AI. Pulled this tag codeproject/ai-server:cuda12_2-2.6.5 . Which version of Yolo should I be using for that and is ALPR able to use this GPU?
When ever I try to enable GPU for the LPR it keeps going back to CPU.
View attachment 199785
Here is the LPR Info where it shows GPU libraries are not installed:
Code:Module 'License Plate Reader' 3.2.2 (ID: ALPR) Valid: True Module Path: <root>/modules/ALPR Module Location: Internal AutoStart: True Queue: alpr_queue Runtime: python3.8 Runtime Location: Local FilePath: ALPR_adapter.py Start pause: 3 sec Parallelism: 0 LogVerbosity: Platforms: all,!windows-arm64 GPU Libraries: not installed GPU: use if supported Accelerator: Half Precision: enable Environment Variables AUTO_PLATE_ROTATE = True CROPPED_PLATE_DIR = <root>/Server/wwwroot MIN_COMPUTE_CAPABILITY = 6 MIN_CUDNN_VERSION = 7 OCR_OPTIMAL_CHARACTER_HEIGHT = 60 OCR_OPTIMAL_CHARACTER_WIDTH = 30 OCR_OPTIMIZATION = True PLATE_CONFIDENCE = 0.7 PLATE_RESCALE_FACTOR = 2 PLATE_ROTATE_DEG = 0 REMOVE_SPACES = False ROOT_PATH = <root> SAVE_CROPPED_PLATE = False Status Data: { "inferenceDevice": "CPU", "inferenceLibrary": "", "canUseGPU": "false", "successfulInferences": 19, "failedInferences": 0, "numInferences": 19, "averageInferenceMs": 138.0 } Started: 28 Jul 2024 12:52:06 PM Pacific Standard Time LastSeen: 28 Jul 2024 12:52:37 PM Pacific Standard Time Status: Started Requests: 16112 (includes status calls)
Here is the system info:
Code:Server version: 2.6.5 System: Docker (b942b79acfaf) Operating System: Linux (Ubuntu 22.04) CPUs: Intel(R) Xeon(R) CPU E3-1230 V2 @ 3.30GHz (Intel) 1 CPU x 4 cores. 8 logical processors (x64) GPU (Primary): Tesla P4 (8 GiB) (NVIDIA) Driver: 550.40.07, CUDA: 11.5.119 (up to: 12.4), Compute: 6.1, cuDNN: 8.9.6 System RAM: 16 GiB Platform: Linux BuildConfig: Release Execution Env: Docker Runtime Env: Production Runtimes installed: .NET runtime: 7.0.19 .NET SDK: Not found Default Python: 3.10.12 Go: Not found NodeJS: Not found Rust: Not found Video adapter info: System GPU info: GPU 3D Usage 13% GPU RAM Usage 1.3 GiB Global Environment variables: CPAI_APPROOTPATH = <root> CPAI_PORT = 32168
I have the similar issue.
CPAI is installed on Promox LXC container with RTX A2000.
I changed the below to force ALPR to use GPU:
1. modulesettings.json:
"GpuOptions" : {
"InstallGPU": true,
2. modulesettings.linux.json:
"ALPR": {
"GpuOptions" : {
"InstallGPU": true
3. ALPR_adapter.py:
def initialise(self) -> None:
# self.can_use_GPU = self.system_info.hasPaddleGPU
self.can_use_GPU = True
4. options.py
# PaddleOCR settings
# self.use_gpu = ModuleOptions.enable_GPU # We'll disable this if we can't find GPU libraries
self.use_gpu = True
Then dashboard shows LPR status with GPU(CUDA), but it seems LPR does not actually use GPU: No change in inference time.
Furthermore, nvidia-smi does not show process PID of LPR, only YOLO.