I'm running my Deepstack in a separate VM, so it was pretty straight forward to spin up another VM running SenseAI. With the "Override server" checkbox it's extremely easy to switch between these two per camera by just checking the box and entering the IP of the SenseAI (Default is DeepStack). So I've played around a bit.
Some questions rose:
1) Is this "just" a wrapped DeepStack?
While pulling the docker image, it was pulling "deepstack". And in the docker logs, in every settings we see "DeepStack":
Code:
------------------------------------------------------------------
Setting Environment variables for Scene Classification
------------------------------------------------------------------
ERRLOG_APIKEY = ed359c3a-8a77-4f23-8db3-d3eb5fac23d9
PORT = 5000
APPDIR = /app/AnalysisLayer/DeepStack/intelligencelayer
CUDA_MODE = False
DATA_DIR = /usr/share/CodeProject/SenseAI
MODE = MEDIUM
MODELS_DIR = /app/AnalysisLayer/DeepStack/assets
PROFILE = desktop_cpu
TEMP_PATH = /app/AnalysisLayer/DeepStack/tempstore
VIRTUAL_ENV = /app/AnalysisLayer/bin/%PYTHON_RUNTIME%/venv
VISION-SCENE = True
2) Performance test
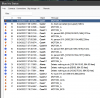
Is there any way to get the exact analysis time per picture from SenseAI? In DeepStack it's just looking at the docker logs:
Code:
[GIN] 2022/06/22 - 14:19:37 | 200 | 743.530125ms | 10.32.1.8 | POST "/v1/vision/detection"
[GIN] 2022/06/22 - 14:19:37 | 200 | 810.86594ms | 10.32.1.8 | POST "/v1/vision/detection"
[GIN] 2022/06/22 - 14:19:37 | 200 | 568.694013ms | 10.32.1.8 | POST "/v1/vision/detection"
[GIN] 2022/06/22 - 14:19:38 | 200 | 578.653844ms | 10.32.1.8 | POST "/v1/vision/detection"
[GIN] 2022/06/22 - 14:19:38 | 200 | 536.494765ms | 10.32.1.8 | POST "/v1/vision/detection"
[GIN] 2022/06/22 - 14:19:39 | 200 | 617.679457ms | 10.32.1.8 | POST "/v1/vision/detection"
In the SenseAI logging window from the UI I just see strange entries like this:
Code:
14:43:00: detection.py: Getting Command from detection_queue took 0.00398 seconds
... which is absolutely not the image proceeing time. No way in 4ms on a CPU based VM. And sometimes this line mentions 8 or 9 seconds ... nope, my server is not that slow.
3. Server load
Both VM's do have the same configuration: Max 15 vCPU (Dell R720, Dual E5-2650L v2, ESXi 6.7U3), 8GB RAM. Running on the same server and same datastore.
Comparing a recorded clip in BI with the "Test & Tuning" --> "Analyze with AI" on - one time with DeepStack, the second time with SenseAI - SenseAI seems to detect more objects during the playback. I can't see a big difference how often the objects are updated with my eye. But again, is there a way to get some performance data in BI itself here?
However, doing exactly this with the same clip, DeepStack drives the common CPU load in the VM to 18%. Sense AI, with the same clip, goes to 38%. Huge load on a "dotnet" process.
As I don't know a way to know:
- how many pictures have been sent for analysis by BI
- what was the exact processing time per picture
... the open question is: Is SenseAI slower in general --> needing double the resources for the same thing, or is it just better multithreading and it does more pictures in the same time because a single pic analysis takes less with the same number of CPU cores.
4. Where to set the mode (low, medium, high) or other environment variables?
In the DeepStack VM, I can configure the mode and other things with environment variables like this in my docker-compose file:
Code:
environment:
- TZ=${TZ}
- PUID=${PUID}
- PGID=${PGID}
- VISION-SCENE=True
- VISION-FACE=True
- VISION-DETECTION=True
- MODE=Medium
- THREADCOUNT=10
There is nothing documented like this for SenseAI? Where can I configure such things, especially the mode?
Maybe
@ChrisMaunder can answer some of these?














")





